Data Lake
Haben Sie sich schon einmal die Frage gestellt, was ein Data Lake ist und wofür es genutzt wird? Dann sollten Sie jetzt weiterlesen, denn in diesem Artikel beleuchten wir genau dieses Thema und klären dabei folgende Fragen/Punkte:
Definition: Was ist ein Data Lake?
Data Lake: Wichtige Funktionen
Vorteile eines Data Lakes
Herausforderungen und Nachteile eines Data Lakes
Beispiel einer Data Lake Implementierung
Data Lake vs. Data Warehouse: Was sind die Unterschiede?

Definition: Was ist ein Data Lake?
Unter dem Erfordernis, stetig wachsende Datenmengen gewinnbringend aus verschiedenen Quellen, sei es Web, Mobil oder aus digital vernetzen Geräten (IoT – Internet of things) zu nutzen, entsteht die Kernidee von Data Lakes (deustch: „Datensee“). In einem Data Lake werden alle Daten abgelegt, die für Business Intelligence, Data Science und Big-Data-Analysen verwendet werden.
Die Daten in einem Data Lake liegen zumeist in folgenden Formaten vor:
- Unstrukturierte Daten (z.B. Sensordaten oder Audiodaten)
- Strukturierte Daten (z.B. formatierte Tabelle)
- Semistrukturierte Daten (z.B. Bilder mit Metadaten)
Im bisherigen Kontext eines Data Warehouses, welches verteilte Datensilos vereint, fokussiert sich ein Data Lake auf die zusätzliche Bereitstellung von nicht relationalen Daten. Daten gelangen zumeist untransformiert, sprich in ihrer nativen Form, in den Datenspeicher, wodurch zwar potenziell mehr Data Cleaning benötigt wird, jedoch auch erweitere Use Cases zur Nutzung der Daten entstehen.
Data Lake: Wichtige Funktionen
Es gilt hervorzuheben, das ein Data Lake vor allem durch folgende Funktionen hervorsticht und für Unternehmen von Interesse sein kann:
- Möglichkeit der Verarbeitung großer und unterschiedlicher Datenmengen (Un- und Semistrukturiert), vor allem im Rohformat
- Hohe Skalierbarkeit im Cloud-Bereich, sowie Verwendung modernster Cluster Technologien (z.B. Apache Spark, Flink). Dies ermöglicht schnelle Bereitstellung, Fault-Tolerance, sowie erweiterte Sicherheitskonzeptintegration
- Universelle Plattform, in die unterschiedliche Datentöpfe gelangen und dadurch eine Single Point of Truth kreiert wird
Vorteile eines Data Lakes
Data Lakes haben aufgrund der Struktur ihrer Rohdaten und dem Analysepotenzial spezielle Vorteile gegenüber Data Warehouses oder singulären Datenbanken:
- Aufgrund der Datenvielfalt lassen sich die meisten Schritte des Kaufverhaltens nachverfolgen und dadurch eine zielgerechte Kundenansprache ableiten
- Das Potenzial den Kundenlebenszyklus anhand diverser Customer Touchpoints zu rekonstruieren, unterstützt Unternehmen bei der richtigen Entscheidungsfindung
- Einheitlichkeit der Daten und die Chance, die Datenqualität mithilfe von abteilungsübergreifenden Data Ingests zu erhöhen
Herausforderungen und Nachteile eines Data Lakes
Auch wenn die Potenziale und Vorteile, die ein Data Lake mit sich bringt, klar erkennbar sind, ist ein kritischer Blick auf die Nachteile zu werfen, die durch eine Implementierung entstehen könnten:
- Data Compliance: Da unterschiedliche Datenbestände im Data Lake existieren, die von diversen Abteilungen stammen, entsteht das Bedürfnis einer durchdachten Compliance, die die Pipelines individuell bewerten muss. Dadurch müssen Daten entweder in einer anonymisierten Form vorliegen und/oder an ein Datenhaltungskonzept gekoppelt werden.
- Data Management: Eine intensive Dokumentation wird erforderlich, damit Datentöpfe nicht exponentiell wachsen und die Nachverfolgbarkeit durch Technical Debts immer geringer wird
- Technische Expertise: Da die Architektur komplex sein kann, wird geschultes Personal erforderlich, das die einzelnen Elemente des Data Lakes kennt und Störungen beheben kann.
Beispiel einer Data Lake Implementierung
In der Cloud finden Sich viele Beispiele für die Implementierung einer Data-Lake-Solution. in der nachfolgenden Abbildung wird eine solche Architektur dargestellt: 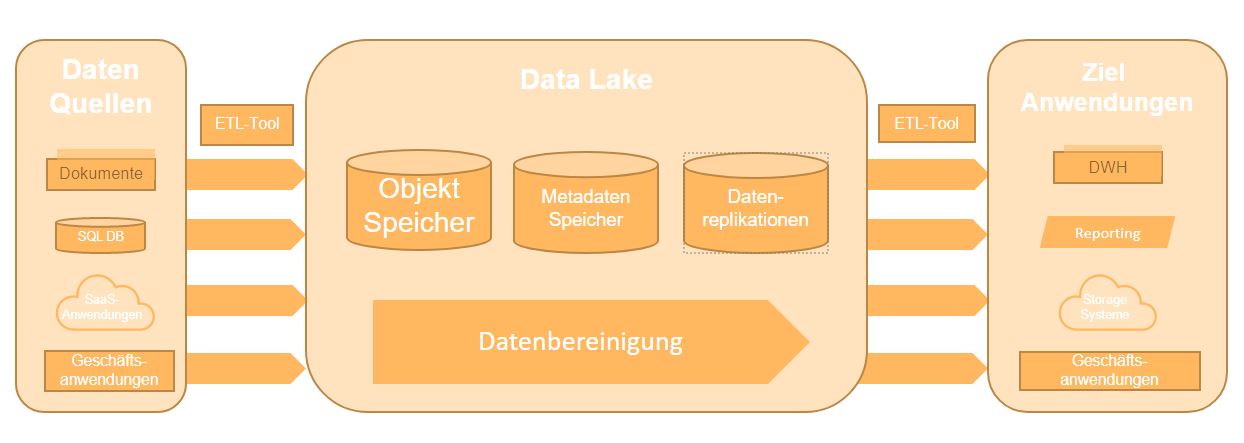
Daten werden im Data Lake auf Basis von verschiedenen Data Layers prozessiert:
- Ingestion Layer (Dateneingang): Im Ingestion Layer werden Rohdaten erfasst und untransformiert in den Data Lake geladen. Diese Daten können aus verschiedenen Systemen (z.B. Business-Anwendungen) entstammen und werden mittels einem ETL-Tool in den Data Lake geladen. Die Daten befinden sich zumeist in einem Objektspeicher, von dem aus diese weiter bearbeitet werden.
- Staging Layer (Datenbereinigung): Im Staging Layer werden Daten bereinigt (Entfernung von Duplikaten und leeren Werten, korrekte Spaltentypen, etc.). Der Staging Layer befindet sich hier bereits innerhalb des Data Lakes, was in einer Cloud dann den besonderen Vorteil hat, das Daten repliziert werden und zugehörige Metadaten separat abgespeichert werden können. Das dient zur Erhöhung der Data Governance und Datenverfügbarkeit.
- Outsourcing Layer: Die bereinigten Daten werden erneut mittels einem ETL-Tool in Zielanwendungen geladen, die diese dann verwenden können. Neben Datenbanken können auch Data Warehouses als Zielort dienen .
Data Lake vs. Data Warehouse: Was sind die Unterschiede?
Betrachtet man ein Data Warehouse im Vergleich zu einem Data Lake, ergeben sich nachfolgende Unterschiede:
| Data Lake | Data Warehouse | |
|---|---|---|
| Datentypen | Strukturierte, semistrukturierte und unstrukturierte Daten | Strukturierte und/oder semistrukturierte Daten |
| Datenschemas | Schema-on-Read: Kein vordefiniertes Schema für Ingest-Prozedur benötigt | Schema-on-Write and -Read: Vordefiniertes Schema für Ingest-Prozedur benötigt |
| Zielgruppen | Business Analysten, Anwendungsentwickler und Data Scientisten | Business Analysten |
Es gilt zu differenzieren, ob ein Data Lake in der Cloud angesiedelt ist. Falls dies der Fall ist, ergeben sich folgende zusätzliche Vorteile:
- Skalierbarkeit: Das starten von neuen Ressourcen ist schneller und einfacher in der Cloud. Hierbei lässt sich zudem inkrementell auf Anzahl der User des Data Lakes skalieren.
- Vernetzung weiterer Services: Seien es Log-Systeme oder Analytics Services, Cloud Provider bieten Anknüpfungen zu Diensten an, die weitere Potenziale schaffen
- Kosteneffektivität: Mittels Pay-as-you-go Abrechnungsmodell wird ausschließlich auf konsumierte Ressourcen abgerechnet