Strukturierte vs. unstrukturierte Daten
Daten sind für die meisten Unternehmen heutzutage goldwert. Doch was steckt eigentlich genau hinter dem Begriff und inwiefern lassen sich Daten voneinander unterscheiden? Genau auf diese Thematik gehen wir an dieser Stelle ein. Denn spricht man von Daten, gibt es solche in vielen unterschiedlichen Formaten, welche sich grundsätzlich in eine von zwei Kategorien einteilen lassen: strukturierte vs. unstrukturierte Daten.
In diesem Beitrag haben wir umfassende Informationen zum Thema zusammengestellt. Darüber hinaus erklären wir, wie Daten verarbeitet/verwaltet werden und was es mit dem Begriff ‚Big Data‚ auf sich hat:
- Was sind Daten?
- Definition: Was sind strukturierte, semistrukturierte und unstrukturierte Daten?
- Strukturierte vs. Unstrukturierte Daten: Der Unterschied im Überblick
- Strukturierte Daten: Vor- & Nachteile
- Unstrukturierte Daten: Vor- & Nachteile
- Datenmanagementsysteme: Wie werden Daten verarbeitet und verwaltet?
- Big Data vs. unstrukturierte Daten: Was ist der Unterschied?
- Ausblick: Wie sieht die Zukunft der Daten aus?
")
Was sind Daten?
Vor der Verbreitung von digitalen Technologien wurden Daten als Informationen und Werte verstanden. Sie wurden zahlenmäßig erfasst und gemessen. Beispielsweise werden in der Informatik Daten in codierter Form verwendet – nämlich mit dem Binärcode als Zahl ‚0‘ oder ‚1‘. Damit solche Daten entschlüsselt (decodiert) werden können, kommen so genannte Standards ins Spiel. Letztere können zum Beispiel Dateiformate woe PDFs oder JPGs sein.
Im Zuge der Digitalisierung sind Unternehmen zunehmend mit einem stetigen Wachstum generierter Datenmengen konfrontiert. Bis vor wenigen Jahren beschränkte sich der Umgang mit der wachsenden Datenmenge auf ein Aufrüsten der Speicherkapazität. Letzteres reicht heutzutage jedoch nicht mehr aus. Denn auch Technologien für Internet-Anwendungen sowie für mobile Apps, sind einer rasanten Entwicklung ausgesetzt – ebenso Handels- und Social-Media-Plattformen.
Die neuen Datenquellen und Datentypen müssen in die Unternehmenssysteme angebunden werden, um sie für Analysen und geschäftliche Entscheidungsfindungen einzubeziehen. Technisch betrachtet, liegen die Herausforderungen vor allem in der Speicherung und in der Analyse der verschiedenen Datentypen: strukturierte, semi- und unstrukturierte Daten.

Was sind strukturierte, semistrukturierte und unstrukturierte Daten?
Definition: Was sind strukturierte Daten?
Strukturierte Daten werden schon seit einiger Zeit insbesondere in traditionellen Systemen und Reports verwendet. Die Generierung von semi- und unstrukturierten Daten steigt durch die oben genannte Technologie-Entwicklung stark an. Immer mehr Unternehmen versuchen, solche Daten anzubinden. Dadurch wird bezweckt, die Analytik auf eine nächste Stufe zu heben, indem alle drei Datentypen einbezogen werden.
Strukturierte Daten liegen in einer standardisierten Form vor und bestehen üblicherweise aus klar definierten Informationen (z. B. Zahlen- oder Textformat).
Schema-on-Write, relationale Datenbanken & Co.
Strukturierte Daten werden, bevor sie in einem Datenspeicher abgelegt werden, in das vorgegebene Format strukturiert. Bevor dies geschieht, werden sie in ein vorgegebenes Format organisiert. Dieser Prozess wird als Schema-on-Write bezeichnet, bei dem folgende Fragestellungen eine Rolle spielen:
- Wie sieht eine Zeile aus?
- Welche Attribute (Spalten) beinhaltet jede Zeile?
- Welche Daten sind zu erwarten?
Typische Datenspeicher für strukturierte Daten sind demnach relationale Datenbanken, bestehend aus Tabellen mit Spalten und Zeilen. In relationalen Datenbanken – oder auch Data Warehouses (DWH) werden Daten in vordefinierte Felder, wie z. B. Name, Adresse oder Produkt-ID formatiert.
Strukturierte Daten sind somit effizient durch relationale Datenbanken oder Data Warehouses verwaltbar. Abfragen können leicht durch aufbauende Anwendungen, wie SQL durchgeführt werden.

Definition: Was sind semistrukturierte Daten?
Semistrukturierte Daten sind einfach gesagt eine Mischung aus strukturierten und unstrukturierten Daten. Sie besitzen keine allgemeingültige Struktur, sondern weisen eine grobe Grundstruktur auf. Sie enthalten also einige konsistente und eindeutige Strukturinformationen, die auf bestimmte Merkmale verweisen. Diese enthalten ausreichend Informationen, sodass im Gegensatz zu unstrukturierten Daten, eine bessere Katalogisierung, Suche oder Analyse vorgenommen werden kann. Außerdem beschränken sich unstrukturierte Daten nicht auf das starre Format strukturierter Daten.
Beispiele semistrukturierter Daten sind:
- E-Mails, die eine Grundstruktur mit ihrer Unterteilung in Betreff, Absender, Empfänger und Text aufweisen. Bei dem Text selbst handelt es sich jedoch um unstrukturierte Daten.
- Bilder, die von einem Smartphone aufgenommen worden sind. Sie weisen eine Grundstruktur mit Attributen wie Geotag, Geräte-ID, selbstbenannte Tags zum Motiv und DateTime-Stempel auf. Das Bild selbst ist wiederum unstrukturiert.

Definition: Was sind unstrukturierte Daten?
Durch die rasante Entwicklung der Technologien für Internet- und mobile Anwendungen entstehen riesige Datenmengen, die vermehrt als unstrukturierte Daten vorliegen. Es handelt sich um Daten, die nicht in einem klassischen tabellarischen Format vorliegen. Solche werden in ihrem nativen Format gespeichert und sind nicht zwingend ordentlich gruppiert oder klassifiziert. Sie werden auch als qualitative Daten bezeichnet, da es sich schlicht um aufgezeichnete Rohdaten handelt.
Zu den unstrukturierten Daten zählen z. B.:
- Audio-,
- Video-,
- Bild-
- oder Textdateien,
die von verschiedensten Quellen generiert werden. Aufgrund ihrer komplexen Anordnung und Formatierung sind sie schwer zu bearbeiten. Deshalb erfolgt die Bearbeitung erst dann, wenn sie verwendet werden. Dieser Vorgang wird als Schema-on-Read bezeichnet. Unstrukturierte Daten benötigen im Unterschied zu strukturierten Daten eine andere Verarbeitungsart. So können beispielsweise bei strukturierten Daten einfache Rechenoperationen, wie Addition oder Durchschnittsberechnung, durchgeführt werden, was bei unstrukturierten Daten nicht möglich ist.
Einige Beispiele der verschiedenen Formate unstrukturierter Daten sind:
- E-Mails
- Social-Media-Posts
- Artikel
- Präsentationen
- Chats
- Daten von IoT-Sensoren oder Satellitenbilder
Aus diesen Formaten können die beinhalteten Daten nicht ohne Weiteres ausgelesen werden, da die Struktur immer eine andere ist.
Gespeichert werden unstrukturierte Daten oft dort, wo sie erfasst worden sind oder in sogenannten Data Lakes – also in undifferenzierten Datenpools.

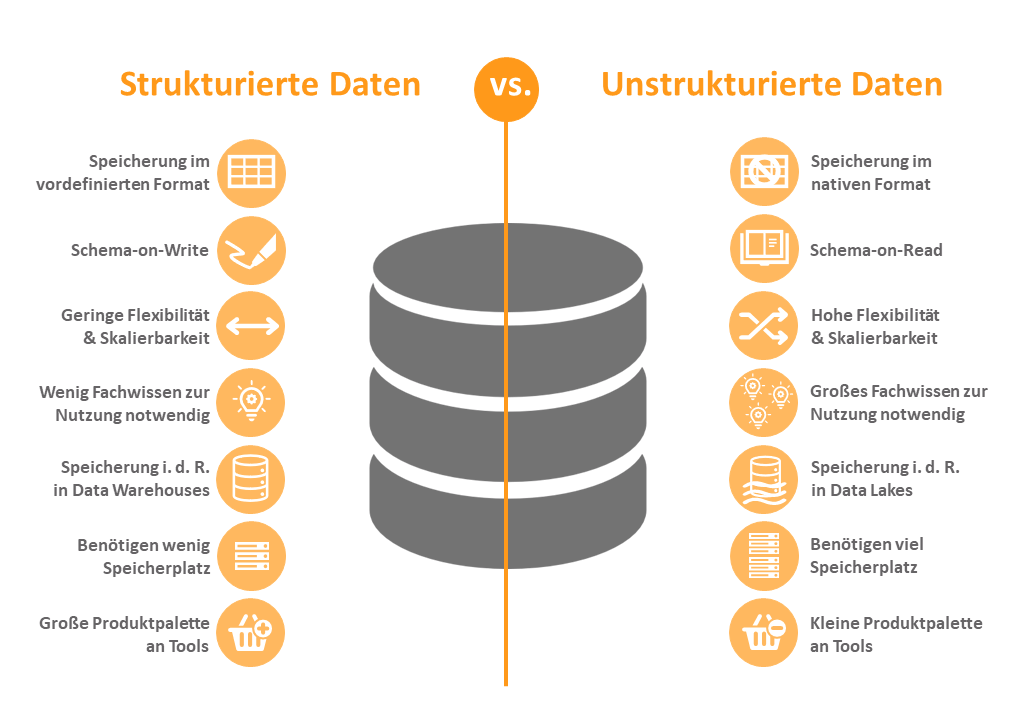
Strukturierte vs. Unstrukturierte Daten: Der Unterschied im Überblick
Bei der Betrachtung strukturierter und unstrukturierter Daten fallen einige Unterschiede auf.
Für einen einfachen Vergleich stellen wir uns strukturierte Daten wie eine Tabelle vor. Jede Spalte beinhaltet ein Attribut und jede Zeile beinhaltet mehrere Werte zu einem Objekt. Liegen dabei numerische Inhalte vor, sind Rechenoperationen durchführbar, wie das Bilden einer Summe oder eines Mittelwertes.
Unstrukturierte Daten können wir uns hingegen als einen Ordner auf einer Festplatte vorstellen. Hier sind verschiedene Arten von Daten gespeichert, wie Multimedia- und Sound-Dateien oder Textdokumente. Die analytische Auswertung dieser Dateien ist nicht, wie bei der Tabelle, ohne eine Vorverarbeitung möglich.
Folgend sind die relevantesten Unterschiede in einer Tabelle zum Vergleich aufgeführt:
")
Strukturierte Daten: Vor- & Nachteile
Durch die Speicherung und Nutzung strukturierter Daten ergeben sich einige Vor- und Nachteile.
Vorteile strukturierter Daten:
- Datenmodell vorab festgelegt (Schema-on-Write): hohe interne Konsistenz und schnelle Durchführung einfacher Analysen
- Robustheit und einfache Pflege
- Einfache Abfrage und Bearbeitung: Einfache Nutzung für nicht-fachliche Anwender
- Einfache Verwendung für Algorithmen
- Große Produktpalette an verschiedenen Tools zur Verwendung und Analyse
Nachteile strukturierter Daten:
Die Nachteile strukturierter Daten hängen primär mit einer mangelnden Flexibilität zusammen:
- Datenmodell vorab festgelegt (Schema-on-Write): geringe Flexibilität für neue Datenquellen und eingeschränkte Anwendungsmöglichkeit
- Geringe Skalierbarkeit
- Begrenzung in Speicheroptionen (i. d. R. relationale Datenbanken oder Data Warehouses)
Praxisbeispiele zu strukturierten Daten
Strukturierte Daten können vom Menschen generiert oder von Maschinen erzeugt sein. Es handelt sich bei strukturierten Daten z. B. um Daten aus den Bereichen Sales (Bestellungen und Umsätze), Enterprise-Resource-Planning (ERP), Logistik, Kundenmanagement oder Webanalytics.
Die einfachste Form vom Menschen generierter, strukturierter Daten sind Tabellenkalkulationen. Werden beispielsweise Kundendaten nicht in eigenen Tabellen, sondern in Datenbanken gespeichert, können Anwendungen für Rechnungsstellungen auf diese Daten zentral zugreifen. Diese Form der Datenstrukturierung hilft, dass Daten aktuell und nicht doppelt vorliegen.
Bei von Maschinen erzeugten, strukturierten Daten können Weblog-Statistiken, Sensordaten oder Point-of-Sale-Daten, wie Barcodes und Stückzahlen genannt werden.
Es gibt eine Bandbreite von Anwendungen für strukturierte Daten. Meisten werden die Daten visuell oder tabellarisch aufbereitet, um zum Stand der Vorgänge im Unternehmen zu informieren und diese Informationen zur Entscheidungsfindung zu nutzen. Solche historischen und deskriptiven Analysen werden unter anderen in folgenden Anwendungen angewandt:
- Reporting: tabellarische Reports und KPIs
- Dashboards: Entwicklung und Visualisierung von Kennzahlen
- Business Intelligence (BI): weiterführende Analysen eines Unternehmens
- Data Science: je nach vorliegenden Daten können Methoden aus dem KI-Bereich angewandt werden
Unstrukturierte Daten: Vor- & Nachteile
Je nach Geschäftsanforderung ergeben sich verschiedene Vor- und Nachteile von unstrukturierten Daten.
Vorteile unstrukturierter Daten:
- Datenmodell wird beim Auslesen festgelegt (Schema-on-Read): hohe Flexibilität für neue Datenquellen und vielseitige Anwendungsmöglichkeit
- Erfassung von Daten in verschiedenen Formaten
- Schnelle und einfache Speicherung ohne Vordefinition
- Hohe Skalierbarkeit
- Eignung für Advanced Analytics und Machine Learning-Algorithmen
Einige Nachteile unstrukturierter Daten:
- Speicherlastig
- Hoher Pflegebedarf
- Kleine Produktpalette an verschiedenen Tools zur Verwendung und Analyse
- Komplexe Abfrage und Bearbeitung: Nutzung nur durch Fachpersonal (Data Scientists)
Dabei stellt die Speicherkapazität heute kein großes Problem mehr dar. Die Herausforderung liegt bei der Erschließung von unstrukturiertem Inhalt.
Praxisbeispiele zu unstrukturierten Daten
Unstrukturierte Daten bieten in vielen Fällen neues Wissen, welches noch nicht erschlossen wurde und die Realität näher abbildet, da Daten aus verschiedenen, z. T. externen Quellen mit in die Analysen aufgenommen werden können. Die hohe Granularität ist dabei ein weiterer Vorteil.
Während strukturierte Daten in einem Data Warehouse immer mit einem Informationsverlust einhergehen (Schema-on-Write), sind unstrukturierte Daten reicher an Informationen (Schema-on-Read). Dies kann zu weiteren Erkenntnissen führen, welche durch herkömmliche Analysen nicht erschließbar sind. Jedoch ist dadurch ein entsprechendes Know-how im Data Science Bereich erforderlich, um diese Daten effizient zu nutzen.
Unstrukturierte Daten finden u. a. Anwendung in folgenden Bereichen:
- Business Intelligence (BI)
- Customer Experience: Customer Journey, Customer Loyality, Next Best Action (NBA)
- Customer Analytics: Kundensegmentierung, Next Best Offer (NBO), Churn Prevention
- Data Science: Data Mining, Text Mining, Sentiments Analytics, Produktentwicklung
So können über moderne BI Technologien, trotz gestiegener Datenmenge und Komplexität, relevante Informationen zeitnah zur Verfügung gestellt werden. Dabei geht es nicht mehr nur um reine Berichte, sondern auch um auffällige Abweichungen und sich abzeichnende Entwicklungen oder Trends in Real-Time. Dafür ist die Verwendung von Daten aus internen und externen Quellen ein guter Ansatz. Denn unstrukturierte Daten können helfen, Informationen aus neuen Blickwinkeln zu betrachten. Beispielweise können Engpässe in der Customer Journey eines Online-Shops oder mehr Informationen zu Kundenanforderungen identifiziert werden.
Darüber hinaus helfen das Speichern und Analysieren von unstrukturierten Daten dabei, um zu erfahren, worüber Kunden in sozialen Medien oder Bewertungs-Websites sprechen. Hierdurch sind Einblicke in die Interessen und das Verhaltensmuster der Kunden möglich. Solche Informationen sind für eine gute Customer Experience und Customer Analytics nützlich und verbessern die Customer Loyality oder die Churn Prevention.
Über Kundensegmentierungen und Marketingkampagnen können dann gezielte NBA und NBO platziert werden. In der Produktentwicklung bringen diese zusätzlichen Informationen die Möglichkeit, neue Produkte und Dienstleistungen mit hoher Nachfrage auf den Markt zu bringen, welche schlussendlich zu höheren Umsätzen führen können.
Best Practices aus dem Data-Science Bereich
Im Data Science-Bereich werden unstrukturierte Daten in Mining-Modelle integriert. Das Data Mining verarbeitet über Maschinelles Lernen große Datenmengen, um neue Zusammenhänge zu erkennen. Das Text Mining hingegen verwendet Daten, die auf natürlich-sprachliche Quellen oder Dokumente basieren.
Mit statistischen Methoden, wie z. B. Natural Language Processing (NLP) werden automatisiert Strukturen, Muster, Bedeutungszusammenhänge und Kerninformationen gewonnen, die Rückschlüsse auf den wesentlichsten Inhalt des Textes geben, ohne ihn komplett lesen zu müssen. Beispielsweise können Wörter wie „Rechnung“, „Geschmack“ oder „Preis-Leistungs-Verhältnis“ erste Hinweise auf relevante Themen wie „Haben wir ein Problem in der Buchhaltung?“, „Haben wir bei der Rezeptur des Schokopuddings den Geschmack der Kundenmehrheit verfehlt?“ oder „Sind wir zu teuer?“ geben.
Best Practice aus dem Customer Experience Bereich
Im Bereich des Customer Experience kann so beispielsweise schnell auf Kundenbeschwerden präzise und im Idealfall problemlösend oder aktuelle Stimmungen („Sentiments“) reagiert werden.
Best Practice aus dem Bereich des Rechtswesens
Anwälte haben eine Vielzahl umfangreicher Dokumente zu lesen und zu bearbeiten. Hier kann Text Mining durch die Extraktion von Informationen und die daraus gewonnenen Visualisierungen und Klassifikationen echte Mehrwerte schaffen und somit die Arbeit von Anwälten effizienter gestalten.
Datenmanagementsysteme: Wie werden Daten verarbeitet und verwaltet?
Um Daten verarbeiten und verwalten zu können, werden Datenmanagementsysteme – auch bekannt als Informationsmanagementsysteme – gebraucht. Solche Systeme funktionieren rechnergestützt und erfassen, speichern, pflegen, verarbeiten, analysieren sowie visualisieren Daten.
Je nach Datentyp werden unterschiedliche Datenmanagementsysteme benötigt.

Datenmanagementsysteme für strukturierte Daten
Die Verwaltung von strukturierten Daten ist aufgrund der standardisierten Form der Daten einfach und bequem. Die relevantesten Technologien zur Speicherung und Verwaltung sind relationale Datenbanken und Data Warehouses.
Relationale Datenbanken sind die klassisch genutzten Systeme. Die Daten werden mithilfe von Tabellen und Verknüpfungen organisiert. Durch Relationen zwischen den Tabellen können Operationen mithilfe von relationaler Algebra durchgeführt werden. Zum Analysieren und Manipulieren der gespeicherten Daten wird häufig die Sprache SQL, z. B. mySQL genutzt.
Data Warehouses sind Systeme, die Daten aus verschiedenen heterogenen Datenquellen (z. B. relationale Datenbanken) für Analysezwecke an zentraler Stelle bündeln und für Analysen zur Verfügung stellen. In diesem Zusammenhang wird oft OLAP (Online Analytical Processing) genannt. Durch OLAP kann sehr flexibel auf die Daten zu Analysezwecken zugegriffen werden. Aus den Informationen und Wissen der zusammengeführten Datenquellen, werden Unternehmen in ihrer Entscheidungsfindung unterstützt. Ein weiteres wichtiges Fundament für die Auswertung von Daten in einem Data Warehouse sind die operativen Systeme, die auch als OLTP (Online Transaction Processing) bezeichnet werden. Anwendung findet OLTP in der EDV-gestützten Durchführung der Geschäftsprozesse von Unternehmen. In der Regel werden OLTP-Systeme für Auftragserfassung, Finanztransaktionen, Einzelhandelsumsätze, Personal- und Lagerbestand sowie CRM angewandt.
Datenmanagementsysteme für unstrukturierte Daten
Bei einer Speicherung von unstrukturierten Daten in Data Warehouses treten schnell Skalierungsprobleme auf, sodass andere Technologien für das Datenmanagement eingeführt wurden. Die Herausforderung an solchen Technologien liegen zwischen einer effizienten Datenablage und einem schnellen Auffinden der Daten für Analysezwecke. Gerade im Bereich Text-Mining sind Algorithmen erforderlich, die große Datenmengen in kurzer Zeit und automatisiert nach Mustern und Zusammenhängen durchsuchen.
Oft werden unstrukturierte Daten dort gespeichert, wo sie erfasst wurden oder in Data Lakes, also in undifferenzierten Datenpools, welche eine massive Speicherkapazität bieten. Dafür sind robuste Rechenzentrums- und Cloud-Architekturen erforderlich.
Eine Möglichkeit dafür sind sogenannte NoSQL-Datenbanken. Diese können Daten beliebigen Schemas speichern und benötigen kein vordefiniertes Format. Bekannte Beispiele solcher NoSQL-Datenbanken sind MongoDB für Informationsdaten oder Apache Cassandra für Multimediadaten. Für Cloud NoSQL Technologien können Azure Cosmos DB oder AWS DynamoDB genannt werden.
Eine andere Möglichkeit sind Big Data Technologien. Diese können z. B. mittels Cloudtechnologie beliebig skaliert werden und basieren nicht auf einen einzigen Server. Dies ist vor allem für große Datenmengen notwendig, aber auch Redundanzen und andere Faktoren spielen eine Rolle. Bekannte Big Data Technologien sind beispielsweise das Open-Source-Framework Apache Hadoop Cluster.
Big Data vs. unstrukturierte Daten: Was ist der Unterschied?
Der Begriff Big Data beschreibt mehrere Aspekte zugleich: Gemein haben diese Big Data-Datensätze, dass sie sich mittels konventioneller Technologien nicht mehr analysieren lassen und Big Data Technologien notwendig sind unabhängig vom Datentyp.

Ausblick: Wie sieht die Zukunft der Daten aus?
Die Zukunft der Daten wird unstrukturiert!
Prognostiziert lässt sich dagen, dass in den nächsten Jahren immer mehr Daten generiert werden – vor allem unstrukturierte und semistrukturierte Daten. Social Media, Voice Assistants, IoT – es gibt eine Vielzahl an Quellen.
Data Lakes und Big Data Analytics: Die Lösung für einfachere Daten-Speicherungen
Data Lakes und Big Data Technologien öffnen die Tore für eine einfachere Speicherung und Verarbeitung. Durch Big Data Analytics, Data Science und Machine Learning wird diese Datenform immer mehr in den Fokus von Data-Driven Companies gestellt und eröffnet den Unternehmen neue Möglichkeiten.
Warum ist es wichtig, den Unterschied verschiedener Datentypen zu kennen?
Für Unternehmen ist es deshalb wichtig den Unterschied zwischen strukturierten, unstrukturierten und semistrukturierten Daten zu kennen und zu verstehen. Konkurrenzfähige Unternehmen werden alle drei Datentypen speichern und analysieren, um die Informationen optimal zu nutzen und damit Entscheidungsfindungen erheblich zu verbessern.
Denn je umfangreicher das Wissen über den Kunden ist, desto zielgerichteter kann auf die Customer Experience und damit auf die individuellen Präferenzen und Wünsche eingegangen werden.
Damit die Daten im Unternehmen weiterhin verlässliche Aussagen treffen, ist die Datenintegrität im Unternehmen ein wichtiger Aspekt. unabhängig davon, ob mit strukturierten oder unstrukturierten Daten gearbeitet wird. Eine Datenintegrität lässt sich am besten mit etablierten Data-Governance– und Datamanagement-Verfahren herstellen.