Dynamische Flächensteuerung: der erfolgreiche Weg zur personalisierten Website
10.03.2023
Dynamische Flächensteuerung in Echtzeit-Architekturen
Durch den immerwährenden Wettbewerbsdruck im E-Commerce und Online-Handel entwickeln Plattformen, Online-Shops und Finanzdienstleister immer innovativere Lösungen, um Produkte und Content personalisiert und umsatzeffizient ausspielen zu können. Dabei etabliert sich immer mehr die dynamische Flächensteuerung. Diese erlaubt es, Kundinnen und Kunden von der ersten bis zur letzten Interaktion aus einer stets gleichen Datenquelle zu „bedienen“. So kann letztlich der Umsatz pro Kund:in als auch das eigene Image gesteigert werden. Die dynamische Flächensteuerung ermöglicht dabei auch eine „In-session“-Content-Anpassung: sollte eine bestimmte Präferenz während eines Webseitenbesuchs erkannt werden, gestaltet und individualisiert diese sich um. Wie dies funktioniert und was man beachten sollte, lesen Sie im nachfolgenden Fachbeitrag.
Dieser Artikel ist zuerst in der Fachzeitschrift BI Spektrum 01/2023 erschienen.
Gerade das Zusammenspiel aus analytischen Modellen, einer in Echtzeit verfügbaren Informationsquelle mit Anspruch an eine hohe Datenqualität und die Anforderung, Ergebnisse in Sekundenbruchteilen berechnen zu müssen, stellt den Betrieb vor besondere Herausforderungen. Denn hierbei müssen MLOps1 und DevOps2 sehr eng und Hand in Hand arbeiten, um die Plattform weiterzuentwickeln und insbesondere um Fehler zu beheben, die unmittelbar Kundenimplikationen haben können. In diesem Artikel soll der Mehrwert einer Real-Time-Architektur am Beispiel der dynamischen Flächensteuerung vorgestellt werden. Weiter wird erläutert, wie die IT-Architektur dafür aussehen muss und wie insbesondere die Entwicklung und der Betrieb aller Beteiligten harmonieren muss, um am Ende einen erfolgreichen Use-Case anbieten zu können.
Dynamische Flächensteuerung
Die dynamische Flächensteuerung hat den Anspruch, die gesamte individuelle Customer Journey eines Kunden oder einer Kundin mit den jeweiligen persönlichen Präferenzen und Vorlieben zu gestalten. Das bedeutet, dass die dynamische Flächensteuerung sowohl Onsite- als auch Offsite-Kampagnen steuert. Dazu werden die Onsite-Kampagnen mit KI-gestützten Programmen und Anwendungen unterstützt. So werden die verschiedenen Seiten einer Homepage (Landing Pages, Product Listing Pages, Product Detail Pages, Search Pages etc.) über Algorithmen voll personalisiert. Zum Einsatz kommen unter anderem Ranking- Listen sowie auch Recommender Systems. Global kann ein Kunde oder eine Kundin auch über eine Nutzersegmentierung einer speziellen Präferenzklasse zugeordnet werden. Die individuellen Bedürfnisse werden dabei jeweils analytisch über KI-Algorithmen inter- und extrapoliert und in einen Single Point of Truth (DWH, Data Mart) gespeichert. Die dynamische Flächensteuerung dient dazu, jede einzelne Interaktion mit dem Kunden zu optimieren und so zu gestalten, dass sie zielführend voll automatisiert abläuft.
Personalisierte Webseite: Mehrwert der dynamischen Flächensteuerung für das Unternehmen
E-Commerce-Plattformen nutzen das Marketingpotenzial ihrer Websites häufig nicht ausreichend aus. Dies bedeutet eine schlechtere Positionierung am Markt und letztendlich weniger Umsatz und eine schlechtere Sichtbarkeit des Unternehmens für Kund:innenLIT1. Im Folgenden wird eine Vorgehensweise skizziert, wie sich Unternehmen in dieser Hinsicht besser aufstellen können.
Das gelingt am besten über eine Vereinigung der neusten Technologien mittels des Ansatzes der dynamischen FlächensteuerungLIT2. Dieser nutzt das volle Potenzial aus den Bereichen der Künstlichen Intelligenz sowie dem Cloud-Engineering. Ein idealer Webshop bietet seinen Kund:innen eine ganzheitliche Lade- und Ausspielungsstrecke an und individualisiert diese entlang der gesamten Customer Journey – sei es auf einer Plattform, einem Shop selbst (onsite) oder über die verschiedenen Marketingkanäle (offsite).
Dabei ist das Schlüsselwort für die dynamische Flächensteuerung die Personalisierung. Das heißt, dass die individualisierte Kundenansprache anhand von Daten zur Person, ihren Vorlieben oder Lifestyles erfolgt. Diese Daten können beispielsweise mittels historischer Käufe, Gesuche, Klicks auf der Website-Oberfläche oder über ihr latentes Verhalten erfasst werden. Gleichzeitig werden genauso Informationen über das „Realtime“-Shopverhalten von Kund:innen gewonnen. So werden Personen entlang einer gesamten Customer Journey passende Produkte und Dienstleistungen angeboten, vom ersten Kontakt bis hin zur Bestellbestätigungsseite. Dies hat den Vorteil, dass der Umsatz maximiert wird, die Bekanntheit des Shops steigt und schlussendlich eine langfristige Kundenbindung entsteht.
Bei der Integration werden zwei Komponenten benötigt: ein schlüssiges KI-Konzept sowie eine leistungsstarke IT-Infrastruktur. Ersteres berechnet das valide Kunden- und Nutzerverhalten sowie persönliche Priorisierungen. Dabei werden zur optimalen Gestaltung der individuellen Customer Journeys verschiedene statistische Modelle eingesetzt, die vor allem mit MLOps entwickelt und implementiert werden. Schlüssige KI-Konzepte umfassen ein Zusammenspiel aus automatisierten Produktlistensortierungen, individuellen Recommendations, einer genauen Nutzersegmentierung sowie Prognosemodellen für kommende Trends und externen Faktoren (unter anderem Wetterdaten). All diese Konzepte verfolgen das Ziel, die für die Kundschaft interessantesten Produkte auf den sichtbarsten Angebotsflächen im Webshop anzuzeigen. Im besten Fall gelingt so ein 1:1-Transfer zum Kunden oder zur Kundin. Die Produktlistensortierung unterstützt dabei den individuellen Aufbau eines Webshops, indem jedem Shop-User genau das ausgespielt wird, was von besonderem Interesse ist. Dies umfasst vor allem die Raster- und Suchergebnisseiten. Dabei muss man zwischen „bekannten“ und „unbekannten“ Nutzer:innen unterscheiden. Für Personen, die über ein Cookie erkannt werden, kann eine viel stärker individualisierte Produktsortierabfolge generiert und angezeigt werden.
Für die nicht erkannten Personen unterstützt eine Nutzer- oder Kundensegmentierung die Ausspielung von individualisierten Inhalten. Ein Algorithmus unterteilt ebendiese User in unterschiedliche, individualisierte Segmente, unter Berücksichtigung von latenten und ganz bewussten Affinitäten. So erkennt das KI-Modelle auch in Echtzeit, welche Präferenz beispielsweise ein erst mal „unbekannter“ Shop-User aufweist. So kann über eine vorab berechnete Produktsortierungsliste in Echtzeit genau der individualisierte Content angezeigt und ausgespielt werden.
Ferner werden individualisierte Recommendations im Shop eingesetzt, sei es auf Rasterseiten, aber vor allem auf Detailseiten. Hier generiert ein KI-Modell für den/die Kund:in personalisierte Komplementär- oder Substitutionsprodukte. Wichtig dabei ist, dass all diese Modelle die Daten aus einer einheitlichen Quelle gewinnen. Dies ermöglicht erst die benötigte Stringenz der Content-Ausspielung entlang der gesamten Customer Journey. Ein User bekommt so vom ersten bis zum letzten Kontakt den passenden, individuell berechneten Content angezeigt, der sich auch während einer Session auf die jeweilige persönliche Präferenz ändern kann. Um diesen Datensupport sicherzustellen, wird ein leistungsstarkes Echtzeit-Framework benötigt.
1 Machine Learning Operations (MLOps) ist ein funktionsübergreifender und kooperativer Prozess der Unternehmen dabei hilft, das gesamte Potenzial eingesetzter Machine Learning Modelle auszuschöpfen.
2 Development IT Operations (DevOps) ist eine Sammlung unterschiedlicher technischer Methoden und eine Kultur zur Zusammenarbeit zwischen Softwareentwicklung und IT-Betrieb.
Notwendige Bestandteile einer Echtzeit-Infrastruktur
Die dynamische Flächensteuerung birgt aus technischer Sicht viele Herausforderungen. So muss die Person, die gerade auf der Website unterwegs ist, bestmöglich erkannt werden. Zusätzlich müssen die Aktivitäten der aktuellen Sitzung mit den bisherigen Verläufen und vortrainierten Ergebnissen zusammengebracht und darauf per ML-Algorithmus das Ergebnis der auszuspielenden Flächen berechnet werden, um es dann wiederum an die Website zurückzuspielen. Zu Beginn bedarf es einer Software, welche die Website-Stream-Daten verarbeiten und die Informationen in Richtung Datenbank und Realtime-Analytics-Software verteilen kann (beispielsweise Kafka oder dessen Alternativen). Um dann zum einen die verschiedenen Kundenidentitäten, zum anderen aber auch alle Website-Events für Analysen, die keine Echtzeit-Verarbeitung benötigen, zu speichern, wird eine Datenbank benötigt, die in der Lage ist, schreibende und lesende Abfragen in großer Anzahl gleichzeitig verarbeiten zu können. Bei einer großen Website mit vielen Nutzern kommen schnell mehrere tausend Requests pro Sekunde zusammen. Hier empfiehlt es sich, bei der Technologie- Auswahl auf Skalierbarkeit zu achten und gegebenenfalls einmal generierte Anfragen in erwarteter Menge zu vertesten.
Kernstück der Architektur für die Umsetzung der dynamischen Flächensteuerung ist aber das Realtime-ML-Framework. Es übernimmt die Aufgabe, die Stream-Informationen der aktuellen Session aufzunehmen. Damit werden dann die Informationen bezüglich der Kundenidentität wie Cookie, Kundennummer oder Ähnliches von der Datenbank abgefragt, um die vollständig verfügbare Identität zu komplettieren. Mit der Kundenidentität werden die vorberechneten Ergebnisse beziehungsweise Präferenzen des Users wiederum aus der Datenbank geladen. Im Anschluss werden diese Daten zusammen mit der aktuellen Website-Journey in ein Modell eingegeben, um die am besten geeigneten Flächen zu ermitteln und diese dann wieder an die Streaming-Engine Richtung Website zu senden. Damit dies für viele parallele Anfragen in „Echtzeit“ passieren kann, sodass die Experience des Website-Users nicht zum Beispiel durch Ladezeiten leidet, bedarf es einer parallelisierten und skalierbaren Softwarelösung. Zwei Open-Source- Frameworks stechen hier heraus und sind als kommerzielle Lösung bei den drei großen Cloud- Anbietern als IaaS-Lösung verfügbar, nämlich Apache Flink und Apache Spark. Apache Flink spielt hierbei seine Vorteile vor allem in großen Clustern aus und kann dort sehr schnell die Ergebnisse in Flink ML berechnen. Hier empfiehlt es sich aber, das Trainieren der Modelle außerhalb von Flink in einem ML-Framework durchzuführen, denn dafür ist Flink nicht konzipiert, da es sich sehr auf den Streaming-Part konzentriert.
Apache Spark kommt wiederum eher als Framework zum Berechnen großer, paralleler Anfragen daher und wurde erst später mittels Spark Streaming echtzeitfähig. Im Gegensatz zu Flink werden die Modelle nicht im Stream berechnet, sondern in einer Art Micro-Batch, das heißt mittels sehr vieler kleiner Batch-ProzesseLIT3. Somit kann Spark auch das Modelltraining übernehmen, spielt aber bei sehr vielen Anfragen die Ergebnisse langsamer zurück als Apache Flink. Insgesamt ist die IT-Architektur keinesfalls trivial und einfach umzusetzen, da viele Komponenten ineinandergreifen müssen, um die richtigen Ergebnisse in sehr schneller Zeit zu berechnen. Genau dies muss in der Entwicklung sowie im Betrieb reibungslos funktionieren. Abbildung 1 gibt einen Überblick über den vorgestellten Prozess.
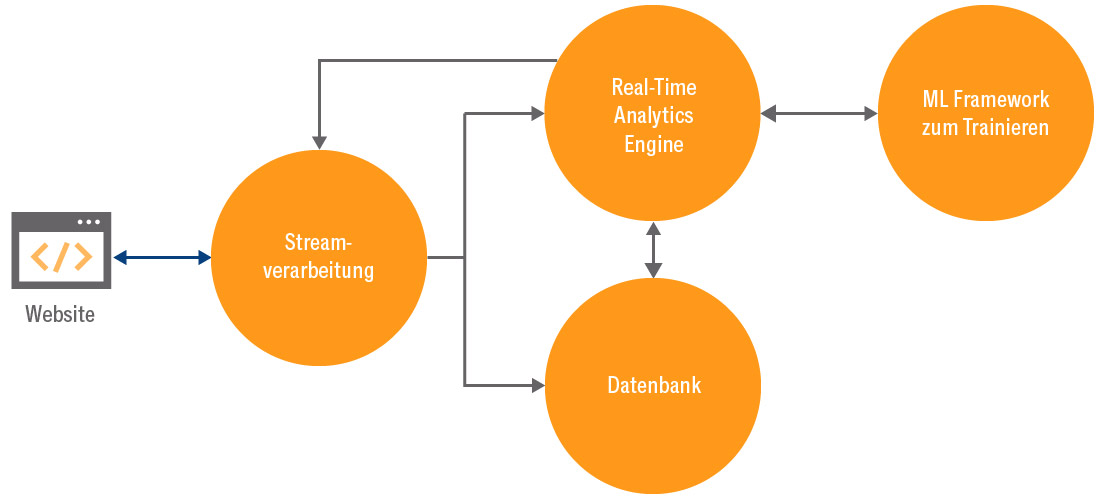
Die wichtigen Schritte zur erfolgreichen Implementierung und Inbetriebnahme
Abgesehen von der Tatsache, dass die dynamische Flächensteuerung ein funktionierendes Framework und valide KI-Modelle benötigt, ist das Zusammenspiel zwischen MLOps und DevOps hier unerlässlich. Beide Prozesse arbeiten größtenteils hybrid, das heißt, beide erbringen Entwicklungsarbeit und Dienstleistungen mit dem gemeinsamen Ziel einer dauerhaften und reibungslosen Abfolge des Systemprozesses. MLOps entwickelt dabei ein produktives MLFramework mit dem Fokus auf Automatisierung und Parallelisierung des Modelltrainings, um die Robustheit und Skalierbarkeit sicherzustellen. Weiter werden die Pipelines standardisiert und systematisch protokolliert. Dieser Schritt ist wichtig, um eine stetige Prüfung des Outputs der KI-Modelle zu gewährleisten. DevOps stellt hierfür das notwendige Grundgerüst bereit, indem die nötigen Container zum Betreiben von KI-Modellen zur Verfügung gestellt werden, um einen nahtlosen Aussteuerungsprozess zu ermöglichen. Mit diesem Schritt kann DevOps die Leistungsbedarfe optimal skalieren – auch bei hybriden Infrastrukturen (On Prem/Cloud).
Des Weiteren überwacht DevOps die Verfügbarkeit und Leistung jeder einzelnen Anwendung mittels ausgearbeiteter Metriken auf verschiedenen Ebenen. Hier ist auch das Release Management verortet, indem definierte Versionsstände ausgesteuert werden, auf die MLOps wieder zugreift. Darüber hinaus erfolgt ein weiterer Code Quality Check durch DevOps. Schlussendlich bietet DevOps auch die Methoden zur Definition und Entwicklung des gesamten Testmanagements. Darunter fallen vor allem Unit-, API- und Performance-Tests. Diese werden gleichzeitig auch automatisiert und fortlaufend eingebunden. Durch dieses Zusammenspiel wird am Ende ein IT-Prozess generiert, der stetig und systematisch erfolgt. Durch diverse Tests wird gleichzeitig ein Früherkennungssystem implementiert, das den Prozess überwacht und nachhaltig verbessert. Ohne das von DevOps bereitgestellte Grundgerüst kann MLOps nicht sein volles Potenzial ausschöpfen, was die Wichtigkeit beider Komponenten im IT-Prozess herausstellt.
Fazit
Durch die Implementierung des Echtzeit-Frameworks gewährleisten beide IT-Ressourcen einen reibungslosen Ablauf der dynamischen Flächensteuerung. Dabei haben wir gezeigt, dass DevOps und MLOps eine vollständige Integration einer End-to-End-Anwendung entwickeln können. Gerade bei ambitionierten Use-Cases ist es unerlässlich, dass beide Komponenten stets partnerschaftlich zusammenarbeiten, um Fehler- und Ausfallraten möglichst gering zu halten. Trotz der Fokussierung auf ihre jeweiligen Kernthemen zeigt sich ein gutes Team vor allem bei der gemeinsamen Arbeit an den Schnittstellen. Das bedeutet, dass die KI-Modelle einerseits auf Genauigkeit und Akkuratesse (MLOps) und andererseits auf Funktion und Skalierbarkeit (DevOps) getestet werden.
Ganz gleich ob Sie künftig Ihre Webseiteninhalte dynamisieren oder die Customer Journey Ihrer Kund:innen verbessern möchten: CINTELLIC ist spezialisiert auf Lösungen im digitalen Kundenmanagement und berät Sie zu Möglichkeiten zur Umsatzsteigerung, Ertragsverbesserung, Kostensenkung oder Effizienzsteigerung durch Prozessautomatisierungen. Vereinbaren Sie gleich einen Gesprächstermin.
PDF jetzt herunterladenLiteratur:
LIT1 Desai, D.: An empirical study of website personalization effect on users intention to revisit e-commerce website through cognitive and hedonic experience. Januar 2019, https://www.researchgate.net/ publication/327536274_An_Empirical_Study_of_Website_Personalization_Effect_on_Users_Intention_to_Revisit_Ecommerce_Website_Through_Cognitive_and_Hedonic_Experience_Proceedings_of_ICDMAI_2018_Volume_2, abgerufen am 4.11.2022
LIT2 IFH Köln: IFH-Studie zur Digitalisierung im Einzelhandel. onlinemarktplatz.de, 13.8.2022, https://www.onlinemarktplatz.de/213119/
ifh-studie-zur-digitalisierung-im-einzelhandel/, abgerufen am 4.11.2022
LIT3 Pointer, I.: Apache Flink: New Hadoop contender squares off against Spark. 7.5.2015, https://www.infoworld.com/article/2919602/
flink-hadoops-new-contender-for-mapreduce-spark.html, abgerufen am 4.11.2022
