Recommender Systems
Sie fragen sich, was sich hinter dem Begriff „Recommender Systems“ verbirgt? Dann sollten Sie jetzt weiterlesen.
Wir geben Ihnen umfassende Infos zum Thema:

Definition: Was sind Recommender Systems und wofür werden sie genutzt?
Recommender Systems ‒ auch als Recommendation Systems oder Empfehlungssysteme bekannt ‒ sind in den letzten Jahren im E-commerce sehr populär geworden. Aber was sind Recommendation Systems? Vereinfacht gesagt, werden Nutzern unterschiedlichster Plattformen, Produkte, Serien oder Songs empfohlen, welche dem bisherigen Konsumverhalten ähneln. Dadurch soll das Interesse des Kunden an weiteren Interaktionen hochgehalten werden. Letztendlich hat ein Recommender System also den Zweck einer Umsatzsteigerung der jeweiligen E-Commerce-Plattform.
Zusammengefasst zentriert ein Recommendation System das Kundenverhalten, mit dem Ziel die Customer Experience zu optimieren. Oder anders formuliert, die Recommender Systems werden durch die Individualisierung der einzelnen Nutzer zur Kundenkommunikationsverbesserung verwendet.
Empfehlungssysteme sind so konzipiert, dass sie auf Basis vieler unterschiedlicher Faktoren dem Benutzer neue Offerten, wie z.B. Filme oder Produkte, machen. Diese Systeme geben eine Vorhersage, welches Produkt ein Nutzer am wahrscheinlichsten kaufen wird bzw. welches weitere Produkt von potenziellem Interesse sein könnte.
Das heißt, ein Recommender System wird benutzt, um relevante und meist personalisierte Inhalte zu empfehlen.

Wie funktionieren Recommender Systems?
Recommender Systems sind Algorithmen, die dazu dienen, Nutzern personalisierte Empfehlungen zu geben. Die grundlegende Idee dahinter ist einfach: Wenn ein Nutzer in der Vergangenheit bestimmte Produkte gekauft, Filme angesehen oder Musik gehört hat, ist es wahrscheinlich, dass er auch an ähnlichen Produkten oder Inhalten interessiert ist. Empfehlungssysteme nutzen diese Informationen, um dem Nutzer oder dem Kunden Empfehlungen zu geben, die auf seinen bisherigen Präferenzen basieren.
Recommender Systems in E-Commerce oder Online Marketing
Im E-Commerce können Recommender Systems dazu beitragen, dass Nutzer schneller und einfacher zu Produkten finden, die sie interessieren und kaufen möchten. Wenn ein Nutzer beispielsweise auf einer Mode-Website nach einem bestimmten Produkt sucht, kann das System ähnliche Produkte vorschlagen, die auf den bisherigen Kauf- oder Suchverhalten anderer Nutzer basieren. Auf diese Weise können Nutzer Produkte entdecken, von denen sie vielleicht gar nicht wussten, dass sie sie suchen oder brauchen.
Ein Beispiel für die Verwendung von Recommender Systems im Online Marketing ist die Personalisierung von Werbung. Basierend auf dem bisherigen Verhalten eines Nutzers, kann ein Recommender System Werbung anzeigen, die besser auf seine Interessen abgestimmt ist. Wenn ein Nutzer beispielsweise oft nach Sportartikeln sucht, kann das System ihm Anzeigen für Sportbekleidung oder Sportausrüstung anzeigen.
Recommender Systems: Drei Methoden & Beispiele
Im Schaubild rechts wird die Aufteilung von Recommendation Systems dargestellt. Es gibt drei Methoden, auf welche ein Recommender System aufbaut. Hierzu zählen das Content-based-, das Collaborative und das Hybrid-Filtering. Beim Collaborative-Filtering gibt eine weitere Unterteilung in zwei Subkategorien: Model-based- und Memory-based-Filtering.
Nachfolgend gehen wir auf jede Methode näher ein und geben Ihnen zu jeder Methodik ein Beispiel, um die Thematik greifbarer zu machen.

1. Methode: Content-based Filtering
Bei der inhaltsbasierten Filterung werden Artikel aufgrund ihres Inhalts und nicht aufgrund der Bewertungen oder Meinungen anderer Nutzer empfohlen. Der Inhalt jedes einzelnen Artikels wird auf der Grundlage von bestimmten Merkmalen oder Eigenschaften des Artikels beschrieben. Wenn wir zum Beispiel Filme betrachten, kann jeder Film mit einer Reihe von Merkmalen beschrieben werden, wie z. B. Filmtitel, Genre, Produktionsjahr, Dauer, Regisseur, Besetzung usw.
Wenn wir Informationen über das Genre haben, können wir leicht herausfinden, welche Benutzer welches Genre mögen, und als Ergebnis können wir Merkmale erhalten, die diesem Benutzer entsprechen, je nachdem, wie er auf Filme dieses Genres reagiert. Auf der Grundlage der zuvor bewerteten Elemente wird ein benutzerspezifisches Klassifikatormodell verwendet, um die Bewertung von Artikeln vorherzusagen, die noch nicht vom Benutzer bewertet wurden. Das hat den besonderen Charme, dass so sehr personalisierte Produkte angeboten werden können, da seine Genre- oder Schauspielerpräferenzen im Modell mit abgebildet werden können.
2. Methode: Collaborative Filtering
Das „kollaborative Filtern“ wird von den meisten Empfehlungssystemen verwendet, um ähnliche Verhaltensmuster unter den eigenen Nutzern zu finden. Mit dieser Technik können Elemente herausgefiltert werden, die den Nutzern auf der Grundlage der Bewertungen oder Reaktionen ähnlicher Benutzer gefallen. Wenn also Nutzer, die einem sehr ähnlich sind, Interesse an einem bestimmten Produkt zeigen, geht das Modell davon aus, dass dieses Produkt auch für den anderen Nutzer interessant sein könnte. Weiter wird das kollaborative Filtern in zwei Subkategorien unterteilt (s. Schaubild oben). Und zwar in die Model- und Memory-based-Ansätze.
Der Model-based-Ansatz nutzt ein bestimmtes Vorhersagemodell, bspw. Matrix Factorisation- oder Clusteringmodelle. Der Memory-based-Ansatz hingegen nutzt z.B. den K-Nearest-Neighbor-Algorithmus (KNN) und unterteilt sich nochmals in zwei Vorgehensweisen, dem benutzerbasiertem- (user-based) und dem produktbasiertem- (item-based) Filtern.
- Diese Methoden benötigen keine weitreichende Datenhistorie zu den jeweiligen Benutzern oder Produkten. Diese Ansätze verwenden einen Ähnlichkeitsscore, basierend auf einem Rankingsystem, welches die historischen Interaktionen bewertet. Daher können diese Methoden für unterschiedliche Webanwendungen leicht implementiert werden.
- Trotz des sehr klaren und logischen Ansatzes bekommt der Algorithmus Probleme, wenn für ein Produkt im Shop zu wenig Nutzerinteraktionen vorliegen. Genauso verhält es sich mit neuen Shopnutzern, für welche es zu wenig Interaktionen auf der Plattform gibt.
User-user collaborative filtering (UUCF)
Die benutzerbasierte kollaborative Filterung ist eine Technik zur Vorhersage, welche Produkte einem Nutzer gefallen könnten, basierend auf den Bewertungen, die andere, diesem Nutzer ähnliche Personen für dieses Produkt abgegeben haben. Ein bekanntes Beispiel für dieses Vorgehen wäre „Customers who bought this item also bought …“, welches auf den Seiten nahezu aller Onlineshops zu finden ist.
Um die Methode zu veranschaulichen, versuchen wir die fehlende Bewertung eines Kunden für ein Buch vorherzusagen:
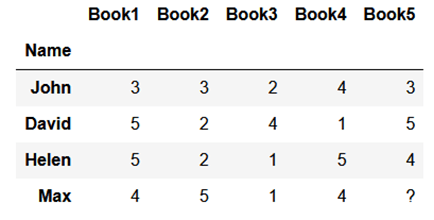
Hier haben wir die Bewertungen von vier Personen für fünf Bücher. Das Ziel ist die fehlende Bewertung des Buches Nummer Fünf (Book5) für den Nutzer Max zu finden. In drei Schritten gehen wir wie folgt vor:
Schritt 1: Datennormalisierung
Die Bewertungen werden in hohem Maße Bandbreite der unterschiedlichen Bewertungen des einzelnen Nutzers beeinflusst. Manche Menschen sind gutherzig und neigen dazu, höhere Bewertungen abzugeben, andere sind bei der Bewertung eher zurückhaltend und können für gute Inhalte eine mittlere Bewertung abgeben. Aus diesem Grund sollten die Daten zunächst normalisiert werden, damit sie verglichen werden können. Eine einfache Technik wäre, die durchschnittliche Bewertung eines Nutzers von seinen Bewertungen abzuziehen.
![]()
In unserem Beispiel werden wir nur die Bücherbewertungen normalisieren, die befüllt sind (also das Buch von 1-4).
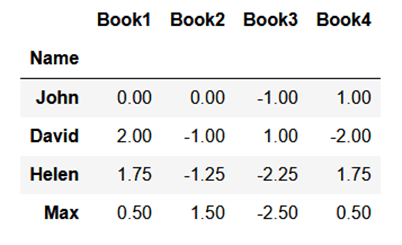
Schritt 2: Suche nach der Ähnlichkeit der Nutzer mit dem Zielnutzer (Max).
Die Ähnlichkeit zwischen den Nutzern ‒ auch bekannt als Abstand zwischen Nutzern ‒ ist eine mathematische Kennzahl, um zu quantifizieren, wie unterschiedlich oder ähnlich die Nutzer zueinander sind. Zu diesem Zweck können verschiedene Metriken verwendet werden. Am meisten benutzt, wird die Pearson-Korrelation oder die Kosinus-Ähnlichkeit.
In diesem Beispiel verwenden wir die Pearson-Korrelation. Die Ergebnisse liegen im Bereich <-1, 1>, wobei 0 bedeutet, dass es keine Abhängigkeiten zwischen den zwei Nutzern gibt. Eine positive Korrelation zwischen den Nutzern bedeutet, dass die Bewertung Nutzer ähnliche Bewertungen für bestimmte Bücher abgeben.
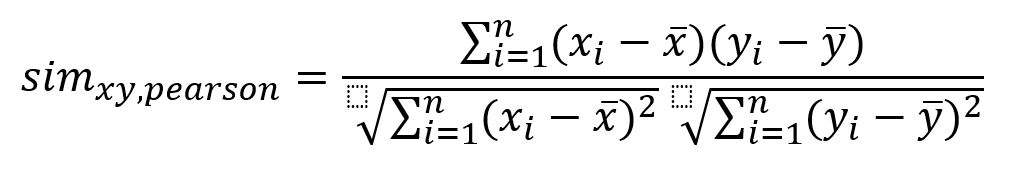
Nach dem die Ratings in obige Formel gesetzt und gerechnet werden, bekommen wir die Ähnlichkeit zwischen Max und den anderen drei Nutzern. Die Angaben in der Pearson-Korrelation Formel werden auch normalisiert, daher können wir hier direkt die Werte von Schritt 1 nehmen.
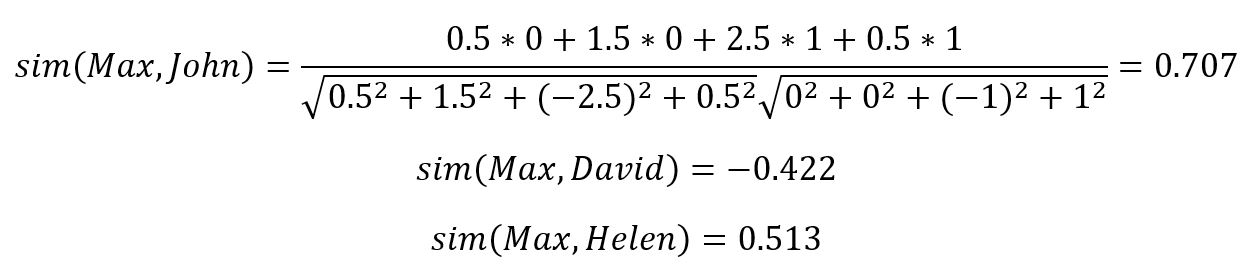
Schritt 3: Vorhersage der fehlenden Bewertung eines Items
Nachdem wir die Ähnlichkeit zwischen Max und den anderen Nutzern berechnet haben, können wir das Rating für Buch 5 für Max prognostizieren. Die vorhergesagte Punktzahl wird als Summe aus dem Mittelwert der Bewertung von Max und dem gewichteten Durchschnitt der Abweichungen vom Mittelwert der anderen Personen berechnet.
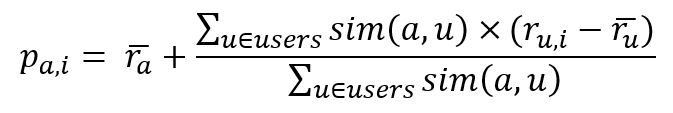
Hier bezeichnet p(a,i) die Vorhersage für Zielnutzer a (Max) für ein Artikel i, und sim(a, u) ist die berechnete Ähnlichkeit zwischen dem Zielnutzer und anderen Nutzern.
![]()
Das errechnete Rating von Buch 5 bei Max wäre also aufgerundet 3. Da wir nur wenig Daten zu Verfügung hatten, wurden die Ratings von allen Personen mitbetrachtet. Bei der Arbeit mit größerer Anzahl von Daten, könnte man hier den KNN Algorithmus anwenden, um erstmal die K-Nächsten-Nachbarn zu finden. Anschließend wäre das Vorgehen äquivalent wie oben beschrieben.
Item-based collaborative filtering
Die produktbasierte kollaborative Filterung ist eine Art von Empfehlungsmethode, die auf der Grundlage der Produkte, die den Nutzern bereits gefallen, oder mit denen sie positiv interagiert haben, nach ähnlichen Artikeln sucht. Anstatt den Benutzer mit ähnlichen Nutzern zu vergleichen, wird beim kollaborativen Filtern für jeden Artikel alle gekauften und bewerteten Produkte des Benutzers mit ähnlichen Produkten abgeglichen und diese ähnlichen Produkte dann in einer Empfehlungsliste kombiniert.
In dem Beispiel zeigen wir wie es funktioniert, indem wir nach einer fehlenden Bewertung von User 3 für den Film Nummer 1 suchen:
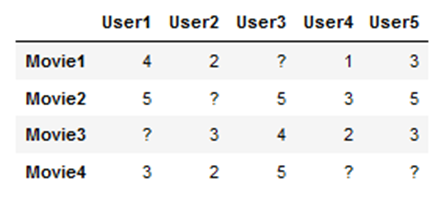
Schritt1: Finde die Ähnlichkeit zwischen den Artikeln
In dem vorherigen Beispiel für benutzerbasierte kollaborative Filterung haben wir die Ähnlichkeit mit Pearson-Korrelation gerechnet. Es gibt auch eine zweite oft benutzte Methode, und zwar die Kosinus-Ähnlichkeit, mit der wir in diesem Beispiel die Ähnlichkeit rechnen werden.
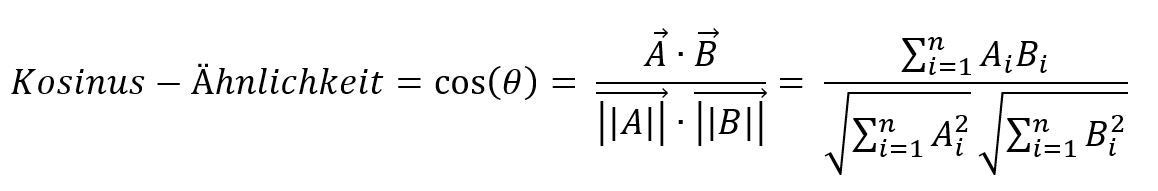
Die grundlegenden Werte für Kosinus-Ähnlichkeit liegen in dem Bereich zwischen –1 und 1. Die 0 bedeutet, wie oben, dass kein Zusammenhang gemessen werden kann. Eine potenziell errechnete 1 bedeutet, dass die Items gleichgerichtet sind. Werte, die somit nahe der 1 liegen, weisen eine hohe Ähnlichkeit auf.
In unserem Beispiel suchen wir die Ähnlichkeit aller Filmkombinationen. Zuerst zeigen wir, wie es manuell für Film 1 und Film 2 aussieht.
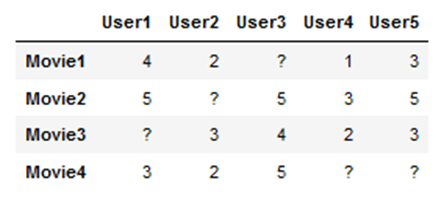
Die Ähnlichkeit für weitere Filmen-Paare wird in der Tabelle unten gezeigt.

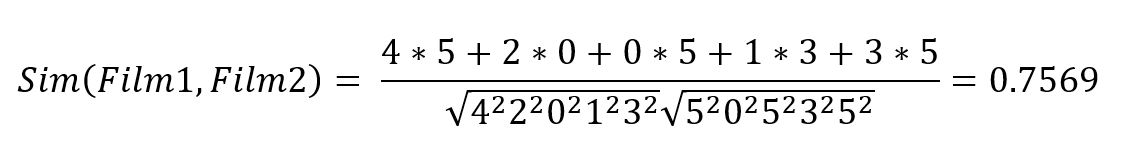
Schritt2: Berechne Empfehlungsscoring
Nach dem die Ähnlichkeit zwischen den Filmen in dem ersten Schritt berechnet wurde, können wir jetzt versuchen das Rating für den ersten Film für User 3 zu finden. Die Vorhersage basiert auf den Ratings für ähnliche Filme und wird als gewichtete Summe der Bewertungen der anderen ähnlichen Produkte berechnet.
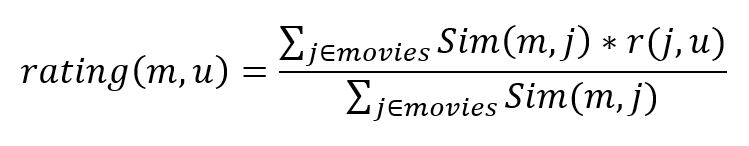
Hier wird das Rating von Film m für User u berechnet, Sim(m, j) bezeichnet die Ähnlichkeit zwischen dem Film m and j und r(j, u) ist das Rating von User u für Film j.
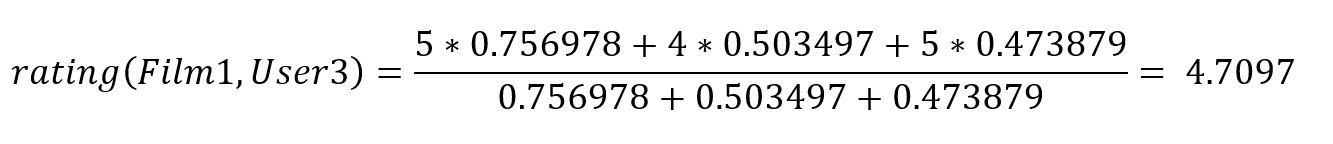
In unserem Beispiel errechnen wir für den Film 1 für User3 also eine hohe Affinität und somit auch eine potenzielle Produktofferte.

3. Methode: Hybrid Filtering
Es kann auch ein hybrides Empfehlungsmodell verwendet werden, das als eine Kombination aus kollaborativer und inhaltsbasierter Filterung betrachtet werden kann. Hybride Ansätze können auf verschiedene Weise implementiert werden, z. B. könnten die Vorhersagen separat mit inhaltsbasierter und kollaborativer Filterung erstellt und dann kombiniert werden. Oder es könnte einfach die Fähigkeiten der kollaborativen Methode zum inhaltsbasierten Ansatz hinzugefügt werde (oder vice versa).
Diese hybriden Ansätze können nützlich sein, um einige der häufigen Probleme zu überwinden, die bei Empfehlungssystemen auftreten, wie z. B. das Problem der geringen Anzahl von Empfehlungen.
Fazit Empfehlungssystem
Zusammenfassend können Recommender Systems als ein Tool innerhalb von Marketing Automation eingesetzt werden, um personalisierte Empfehlungen zu geben und die Interaktion mit Kunden zu verbessern. Dabei dreht sich alles um die individuellen Bedürfnisse und Interessen des Nutzers oder der Kundin. Dabei unterliegen die Systeme der geschäftseigenen Business Rule, ob Substitutions- oder Komplementärinhalte angezeigt werden. In beiden Fällen zahlen die Empfehlungsdienste auf den Umsatz, aber auch das Unternehmensimage ein. Vor allem Zweiteres wird häufig unterschätzt, denn ein Kunde, der relevanten Content sieht, konvergiert schneller zu einem rentablen Stammkunden.
