Web Mining
In diesem Artikel geht es ums Web Mining – doch was ist das genau und in welchem Kontext wird es angewendet? Hier finden Sie alle Informationen.
Definition: Was ist Web Mining?
Drei Arten von Web Mining
Web Content Mining: Definition, Techniken & Co.
Web Structure Mining: Definition, Arten & Co.
Web Usage Mining: Definition, Kategorien & Co.
Exkurs: Web Scraping – So können Daten extrahiert werden

Definition: Was ist Web Mining?
Beim Web Mining werden Data-Mining-Techniken angewendet, um Informationen aus Webdokumenten zu extrahieren und für weitere Anwendungen verfügbar zu machen. Mithilfe automatisierter Methoden aus den Bereichen Information Retrieval, maschinelles Lernen, Statistik, Mustererkennung und Data-Mining werden sowohl strukturierte als auch unstrukturierte Daten aus Webseiten, Protokollen und Linkstrukturen extrahiert.
Mittels Web Mining kann beispielsweise die Leistung von Web-Suchmaschinen durch Klassifizierung von Web-Dokumenten verbessert werden, man kann das Verhalten von Website-Besuchern prognostizeren oder auch die Landing Pages optimieren.
Drei Arten von Web Mining
Es kann zwischen drei Arten von Web Mining unterschieden werden. Web Content Mining extrahiert die Daten von der Website, Web Structure Mining kümmert sich um die Datenextrahierung über Links und Web Usage Mining liefert die Informationen vor allem aus Log Dateien, z.B. welche Muster es in der Navigation auf der Seite gibt.
In diesem Wiki-Artikel werden wir uns hauptsächlich auf Web Content Mining konzentrieren.
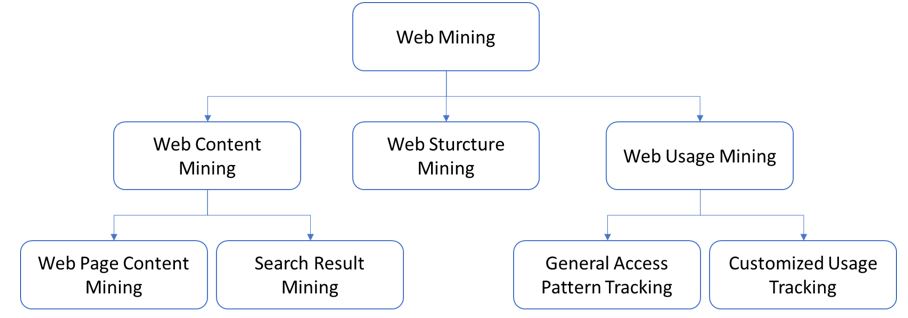
Web Content Mining: Definition, Techniken & Co.
Definition: Was versteht man unter Web Content Mining?
Web Content Mining umfasst Mining, Extraktion und Integration von Informationen von Webseiten. Inhaltsdaten können aus Text, Bildern, Audio, Video oder strukturierten Datensätzen, wie Listen und Tabellen, bestehen. Bei Web Content Minnig können zwei Ansätze unterschieden werden, und zwar Database und Agent-based Ansatz.
- Beim Database-Ansatz wird die Struktur der Seite eingelesen, um eine Webseite in eine Datenbank umzuwandeln, sodass ein besseres Informationsmanagement und eine bessere Abfrage der Informationen dieser Webseite ermöglicht wird.
- Der Information Retrieval (IR) Ansatz verwendet sogenannte Webagenten, um relevante Informationen von Webseiten zu sammeln. Ein Web-Agent ist ein Programm, das eine Website aufruft und die Informationen herausfiltert, an denen der Benutzer interessiert ist. Es gibt drei Arten vom agentenbasierten Ansatz: Intelligente Suchagenten, Informationsfilterung/Kategorisierung und personalisierte Web-Agenten.
Die Daten von Webinhalten teilen sich in folgende Kategorien:
- Unstructured Data – freier Text
- Structured Data – Tabellen oder Datenbank-generierte HTML-Seiten
- Semi-Structured Data – HTML
- Multimedia Data – Bilder, Audioaufnahmen, Video
Techniken und Data Processing
Der Abruf von Informationen einer Website kann in folgenden Schritten erfolgen:
-
Extrahierung von Text aus HTML
Bevor man mit dem Mining starten kann, müssen die Website-Inhalte heruntergeladen werden. Das kann mit einem Scraper geschehen. Dafür gibt es ein Beispiel in dem Abschnitt für Web Scraping.
-
Stemming durchführen
Stemming reduziert die unterschiedlichen Varianten eines Wortes zu einem gemeinsamen Wortstamm, z.B. von „Wortes“ oder „Wörter“ zu „Wort“
-
Stoppwörter entfernen
Die Stoppwörter wir z.B. der, die, das, und, auch, oder, ein, einer usw. sollten erstmal entfernt werden, da die sehr häufig auftreten, aber keine Relevanz für Textinhalte besitzen.
-
Berechnen sammlungsweiter Worthäufigkeiten (DF)
-
Berechnen von Termhäufigkeiten pro Dokument (TF)
Unstructured Data Mining Techniken
Web Content Mining erfordert die Anwendung von Data Mining und Text Mining Techniken. Zu den Text Mining Techniken zählen Information Extraction, Topic Tracking, Summarization, Categorization, Clustering und Information Visualization.
Information Extraction
Informationsextraktion ist ein Prozess, in welchem Informationen aus unstrukturierten Daten extrahiert und in ein strukturiertes Datenformat umgewandelt werden. Um dies zu ermöglichen, wird Pattern Matching benutzt. Es ermittelt die Schlüsselwörter und Phrasen und deren Verbindungen untereinander innerhalb des Textes. Ein gutes Beispiel für IE wäre Extrahierung des Datums aus einer E-Mail, welches später in den Kalender hinzugefügt werden könnte.
Topic Tracking
Diese Technik prüft die vom Benutzer angesehenen Dokumente und untersucht ihre Profile. Dann werden neue Dokumente vorhergesagt, die den Interessen der Nutzer entsprechen.
Summarization
Diese Methode wird verwendet, um die Länge des Dokuments zu reduzieren, aber die wichtigen Punkte beizubehalten. Die kurze Zusammenfassung soll dem Benutzer die Entscheidung erleichtern, ob er ein Dokument lesen soll oder nicht.
Categorization
Die Kategorisierung hilft, das Hauptthema des Inhalts zu finden. Dies kann beispielsweise durch Häufigkeiten von Wörtern innerhalb des Dokuments geschehen.
Clustering
Beim Clustering geht es darum, eine Menge unmarkierter Texte so zu gruppieren, dass die Texte im selben Cluster einander ähnlicher sind als die Texte in anderen Clustern. Solche Cluster helfen, Nutzern auf Basis der bisherigen Nutzung weitere Texte vorszuschlagen, welche ähnliche Inhalte haben.
Information Visualization.
Unter Informationsvisualisierung versteht man die grafische Darstellung von, z.B als Karte oder Grafik. Das hilft den Benutzern, den Inhalt zu interpretieren und analysieren.
Structured Data Mining Techniken
Strukturierte Daten sind in der Regel die Datensätze, die aus einer Datenbank abgerufen und auf den Webseiten in der Form von einer Tabelle oder eines Formulars angezeigt werden. Solche Daten können mit Extraktionstechniken für strukturierte Daten extrahiert werden, wie Web Crawler, Wrapper Generation, Page Content Mining.
Ein Web-Crawler beispielsweise ist ein automatisiertes Skript, das die HTML-Struktur im Web durchläuft und die heruntergeladenen Seiten indiziert, damit der Benutzer effizienter suchen kann. Sie werden verwendet, um Daten aus Webseiten zu extrahieren.
Web Structure Mining: Definition, Arten & Co.
Das Ziel von Web Structure Mining ist die Analyse der Struktur einer Website. Web Structure Mining befasst sich hauptsächlich mit der Hyperlink-Struktur. Es untersucht die Strukturen wie HTML- und XML-Tags und sammelt Informationen über die Organisation der Seite.
Web Structure Mining verwendet u.a. die Graphentheorie, um die Knoten- und Verbindungsstruktur einer Website zu analysieren. Die Graphentheorie befasst sich mit Graphen, also mathematischen Strukturen, die zur Modellierung paarweiser Beziehungen zwischen Objekten verwendet werden. Ein Graph in diesem Zusammenhang besteht aus Eckpunkten (auch Knoten oder Punkte genannt), die durch Kanten (auch Verbindungen oder Linien genannt) verbunden sind.
Web Structure Mining kann in zwei Arten unterteilt werden:
1. Extraktion von Mustern aus Hyperlinks im Web
Ein Hyperlink ist eine strukturelle Komponente, die die Webseite mit einem anderen Ort (z.B. einer weiteren Webseite) verbindet
2. Mining der Dokumentenstruktur
Analyse der baumartigen Struktur von Seiten zur Beschreibung der Verwendung von HTML- oder XML-Tags
Web Usage Mining: Definition, Kategorien & Co.
Web Usage Mining, auch bekannt als Web Log Mining, ist die Extraktion von Informationen aus Webprotokollen, um die Interessen der Nutzer zu analysieren. Typische Datenquellen sind alle Arten von Protokolldateien, Benutzerprofile, Sessions und Cookies, sowie Metadaten: Seitenattribute, Inhaltsattribute und Nutzungsdaten.
Web Usage Mining wird in zwei Kategorien eingeteilt: das Tracking allgemeiner Zugriffsmuster (en: general access patterns tracking) und das Tracking der individuellen Nutzung (en: customized usage tracking). Beim allgemeinen Tracking von Zugriffsmustern wird die Historie der Webseitnutzung ausgewertet, um die Zugriffsmuster und Trends zu verstehen und, darauf aufbauend, die Struktur der Webseite zu verbessern. Sobald sich die Analyse auf einen einzelnen Benutzer konzentriert, geht es um Customized Usage Tracking.
Web Usage Mining erfolgt in drei Phasen: Preprocessing, pattern discovery and pattern analysis.
1. Preprocessing
Protokolldaten können sehrunstrukturiert, unvollständig oder inkonsistent sein, daher ist die Vorverarbeitung eine wichtige Phase beim Web Log Mining. Als Erstes müssen die Rohdaten bereinigt werden, d. h. alle redundanten, unbrauchbaren, falschen oder unzureichenden Daten werden entfernt. Der nächste Schritt ist die Benutzeridentifizierung. Der Benutzer kann durch eine Kombination aus IP-Adresse, Name des Rechners, Browser-Agent und einigen anderen für den Benutzer relevanten Informationen identifiziert werden.
Weitere Schritte der Datenaufbereitung sind die Identifizierung von Sessions, der Abschluss von Pfaden und die Identifizierung von Transaktionen. Die Identifizierung der Sitzung ist wichtig, um die Anzahl der Seiten zu ermitteln, die ein einzelner Benutzer während eines Besuchs auf einer Website nacheinander besucht. Eine Benutzersitzung ist eine Reihe von Seiten, die von einem Benutzer besucht werden, wobei jede neue IP einen neuen Benutzer bedeutet. Das Problem kann auftreten, wenn ein Proxy-Server verwendet wird und mehrere Benutzer mit derselben IP-Adresse kommen.
Die Pfadvervollständigung kann ein weiteres kritisches Problem sein, das gelöst werden muss. Das Problem kann auftreten, wenn die Aktionen eines Benutzers nicht im Zugriffsprotokoll aufgezeichnet werden. Schließlich ist die Identifizierung von Transaktionen optional und hängt von dem Wissen ab, das aus der Webseite gewonnen werden soll. Sie beschreibt die Gruppierung einer Reihe von Vorgängen, die logisch identisch sind und innerhalb eines bestimmten Zeitraums durchgeführt werden.
2. Pattern Discovery
In dieser Phase wird aus den zuvor bereinigten Daten nützliches Wissen abgeleitet, indem verschiedene Techniken aus unterschiedlichen Bereichen, wie Data Mining, maschinelles Lernen, statistische Methoden und Mustererkennung, angewendet werden. Die amhäufigsten verwendeten Methoden sind Assoziationsregeln, sequenzielle Mustererkennung, Klassifizierung und Clustering.
Die Assoziationsregel ist eine der grundlegenden Regeln des Data Mining und wird hauptsächlich beim Web Usage Mining verwendet. Sie hilft dabei, Korrelationen zwischen Webseiten zu entdecken, die während einer Benutzersitzung wiederholt erscheinen.
Beim Web Usage Mining werden sequenzielle Muster verwendet, um Navigationsmuster der Benutzer zu finden, die in den Transaktionen häufig vorkommen. Sie können als ähnlich wie Assoziationsregeln betrachtet werden, allerdings wird bei sequenziellen Mustern der Zeitbereich mit einem bestimmten Attribut von Interesse betrachtet.
Die Klassifizierung/Clustering ist ein automatisierter Prozess der Zuordnung eines Benutzers auf der Grundlage seines Surfverhaltens oder eines anderen Attributs zu einer Klasse. Es gibt mehrere Algorithmen des maschinellen Lernens, die dafür verwendet werden können, wie z. B. Entscheidungsbaum, naive Bayes oder Support-Vektor-Maschine. Die Klassifizierung bildet die Grundlage für weitere Web Usage Mining-Anwendungen wie Profilbildung. Später können auf der Grundlage des klassifizierten Benutzerprofils effiziente Personalisierungen und Empfehlungen ausgesprochen werden.
Seiten-Clustering-Techniken identifizieren Gruppen von Seiten, die konzeptionell verwandt sind. Dies kann durch die Messung von Ähnlichkeiten zwischen zwei Entitäten erfolgen, z. B. durch die Verwendung der Euklidischen Distanz.
3. Pattern Analysis
Die letzte Phase des Web Usage Mining umfasst die Validierung und Interpretation der gefundenen Muster. In diesem Schritt werden alle irrelevanten Regeln oder Muster aussortiert und nur die relevanten extrahiert. Die Daten können in einem Datenwürfel oder einem Data Warehouse gespeichert werden, wo verschiedene OLAP-Operationen (Online Analytical Processing) angewendet werden können.
Exkurs: Web Scraping - So können Daten extrahiert werden
Web Scraping wird verwendet, um Daten von Websiten zu extrahieren. Es kann manuell durchgeführt werden, jedoch bezieht sich dieser Begriff in der Regel auf einen automatisierten Prozess der Datenextraktion, der mit Hilfe eines Bots oder Webcrawlers durchgeführt wird. Die Daten von der Website werden kopiert und in einer zentralen Datenbank oder Tabellenkalkulation gespeichert und für die weitere Verwendung verarbeitet.
In Web Scraping können zwei Ansätze erkannt werden:
- Herunterladen des HTML-Inhalts direkt von der Website. Dieser Ansatz ist einfach, aber wenn sich die Struktur des Front-Ends der Website ändert, muss der Code entsprechend angepasst werden.
- Abfrage der API durch Simulation der Anfragen. Dies kann verwendet werden, wenn die Daten in der API gespeichert sind und die Website die API jedes Mal abfragt, wenn sie geladen wird. Bei dieser Methode sind die empfangenen Daten besser strukturiert und stabiler (Änderungen im Frontend sind hier irrelevant), was diesen Ansatz vorteilhaft macht. Die Umsetzung dieses Ansatzes ist jedoch komplizierter als der erste, insbesondere wenn eine Authentifizierung erforderlich ist.
Anwendungsbeispiele für Web Scraping
Web Scraping wird in vielen verschiedenen Bereichen eingesetzt, sei es für geschäftliche oder private Zwecke. Hier werden ein paar der bekanntesten Beispiele für Web Scraping genannt.
Preisvergleich: Da dynamische Preismodelle immer beliebter werden, ist es wichtig, die Preise auf der Grundlage von Konsumtrends und dem Verhalten der Mitbewerber zu optimieren. Das Crawlen anderer E-Commerce-Websites kann dabei helfen, diese Daten im Auge zu behalten und schließlich die Preise entsprechend anzupassen.
Werbeanzeigenüberwachung: Die Vielzahl von Werbeanzeigen im Internet macht es schwer, den Überblick darüber zu behalten, was die Konkurrenz gerade bewirbt. Mit Web Scraping kann man die am häufigsten erstellten Anzeigen verfolgen. So könnte man leicht neue Trends, neue Kampagnen oder Einblicke in die Zielgruppen erkennen. Die Erkenntnisse können genutzt werden, um die eigene Werbung zu verbessern.